Latency is a major design risk for most embedded software engineers. The Embedded SDK provides several methods for measuring
the extra latency imposed by the software.
Interrupt Latency
Interrupt latency can be defined as the amount of time that elapses from when an interrupt occurs to when the interrupt is serviced
(gets to the interrupt routine). Each type of microcontroller will have a different minimum amount of interrupt latency that is always
present because it is caused from the hardware. This is dependent upon the CPU architecture. Figure 1. shows a time line that
illustrates the minimum latency.
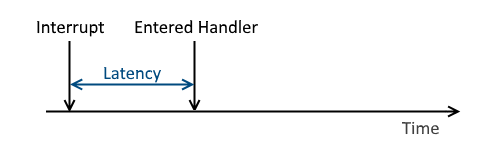
Figure 1 - Illustrates a time line for typical interrupt latency.
In order to support system calls for interrupts, the kernel temporarily disables interrupts while it modifies critical data structures.
Although the kernel has been designed to keep the time the interrupts are disabled to a minimum, it does add a small amount of latency to
those disabled interrupts. Figure 2 illustrates a time line with the added latency that is caused from disabling interrupts.
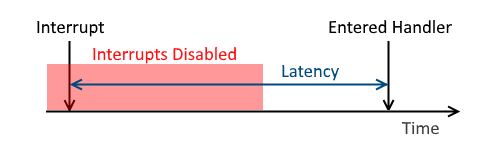
Figure 2 - Illustrates a time line where latency was increased due to interrupts being disabled.
Since it is important to know the worst-case interrupt latency for a system, the kernel contains the ability to measure the maximum amount
of time that interrupts have been disabled. If CFG_LOCKSTATISTICS is enabled within kernel_cfg.h, the kernel will use a stopwatch to
capture the maximum amount of time that interrupts have been disabled.
The maximum time interrupts have been disabled can be retrieved within the device using STAT_MaxIsrLock(). The returned value will be in units
of timestamp ticks which has a defined frequency of CFG_TSTICKSPERSECOND within kernel_cfg.h. This value can also be viewed using a debugger
by looking at the value of the symbol lock_stats.isr.max. The Kernel Probe can also be used to view the maximum interrupt disable time.
Thread Latency
Thread latency is defined by the amount of time that elapses from the moment a thread is marked ready to execute to the moment the thread actually
begins executing. Thread latency will mostly depend upon the priority of the thread. The kernel will always choose to execute the highest priority
thread. Thread latency can never be guaranteed, even for the highest priority thread, since an interrupt can always preempt a thread. Therefore,
interrupt handlers should be kept as short as possible and defer long processing for a thread.
Besides interrupts, both interrupt locks and thread locks can attribute to increased latency for a thread. The maximum time threads have been locked
from switching can be retrieved using STAT_MaxThreadLock(). The returned value will be in units of timestamp ticks which has a defined frequency
of CFG_TSTICKSPERSECOND within kernel_cfg.h. This value can also be viewed using a debugger by looking at the value of the symbol lock_stats.thread.max.
The Kernel Probe can also be used to view the maximum thread lock time.